1.4 formatR 代码自动化排版
问题
如何写出让别人看得懂,且符合规范的代码呢?

引言
新手写的代码,大都不注重代码规范,以为实现功能就算完成了。这种代码不仅别人不愿意读,过几个月后再看自己都会觉得很烂。不仅仅新手如此,大多数程序员写的代码都没有考虑如何让别人看着更方便。程序员最痛苦的事情,不是每天加班写程序,而是每天加班读懂别人写的程序。最后,有人实在忍受不了其他人的丑陋代码,便开始制定代码编程规范,又有人实现代码的自动化排版工具。formatR就是这样的一个R语言自动化排版的工具。
1.4.1 formatR介绍
formatR包是一个实用的包,提供了R代码格式化功能,可以自动设置空格、缩进、换行等代码格式,让代码看起来更友好。formatR包中的API主要有下面5个函数。
- tidy.source: 对代码进行格式化
- tidy.eval: 输出格式化后的R代码和运行结果
- usage: 格式化函数定义,并按指定宽度输出
- tidy.gui: 一个GUI工具,支持编辑并格式化R代码
- tidy.dir: 对某个目录下,所有R脚本进行格式化
1.4.2 formatR安装
本节使用的系统环境是:
- Win7 64bit
- R: 3.0.1 x86_64-w64-mingw32/x64 b4bit
注:formatR同时支持Win7环境和Linux环境。
formatR的安装过程如下。
~ R # 启动R程序
> install.packages("formatR") # 安装formatR包
library(formatR) # formatR加载
1.4.3 formatR的使用
1. 字符串格式化
tidy.source函数,以字符串作为输入参数,对代码格式化。
> tidy.source(text = c("{if(TRUE)1 else 2; if(FALSE){1+1", "## comments", "} else 2}"))
{
if (TRUE)
1 else 2
if (FALSE) {
1 + 1
## comments
} else 2
}
通过执行tidy.source函数,把代码进行了重新格式化,让我们一眼就可以看得懂。
2. 文件格式化
messy.R是一个不太规范的R程序文件。我们读入这个文件,然后通过tidy.source函数,以文件对象作为输入参数,进行代码格式化。
> messy = system.file("format", "messy.R", package = "formatR")
> messy
[1] "C:/Program Files/R/R-3.0.1/library/formatR/format/messy.R"
messy.R 的原始代码输出:
> src = readLines(messy)
> cat(src,sep="\n")
# a single line of comments is preserved
1+1
if(TRUE){
x=1 # inline comments
}else{
x=2;print('Oh no... ask the right bracket to go away!')}
1*3 # one space before this comment will become two!
2+2+2 # 'short comments'
lm(y~x1+x2, data=data.frame(y=rnorm(100),x1=rnorm(100),x2=rnorm(100))) ### only 'single quotes' are allowed in comments
1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1 ## comments after a long line
'a character string with \t in it'
## here is a long long long long long long long long long long long long long long long long long long long long comment
格式化后的代码输出:
> tidy.source(messy)
# a single line of comments is preserved
1 + 1
if (TRUE) {
x = 1 # inline comments
} else {
x = 2
print("Oh no... ask the right bracket to go away!")
}
1 * 3 # one space before this comment will become two!
2 + 2 + 2 # 'short comments'
lm(y ~ x1 + x2, data = data.frame(y = rnorm(100), x1 = rnorm(100), x2 = rnorm(100))) ### only 'single quotes' are allowed in comments
1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 ## comments after a long line
"a character string with \t in it"
## here is a long long long long long long long long long long long long long long long long
## long long long long comment
可以看出,格式化后的输出,经过了空格、缩进、换行、注释等处理,代码可读性就增强了。
3. 格式化并输出R脚本文件
新建R脚本文件demo.r。
~ vi demo.r
a<-1+1;a;matrix(rnorm(10),5);
if(a>2) { b=c('11',832);"#a>2";} else print('a is invalid!!')
格式化demo.r。
> x = "demo.r"
> tidy.source(x)
a <- 1 + 1
a
matrix(rnorm(10), 5)
if (a > 2) {
b = c("11", 832)
"#a>2"
} else print("a is invalid!!")
输出格式化结果到文件:demo2.r,如图1-3所示。
> f="demo2.r"
> tidy.source(x, keep.blank.line = TRUE, file = f)
> file.show(f)
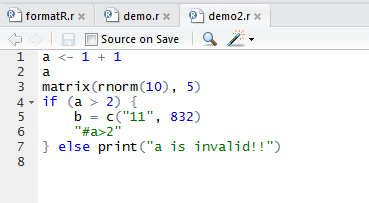
图1-3 输出格式化结果到文件
4. 输出格式化代码和运行结果
使用tidy.eval函数,以字符串形式,执行R脚本:
> tidy.eval(text = c("a<-1+1;a", "matrix(rnorm(10),5)"))
a <- 1 + 1
a
## [1] 2
matrix(rnorm(10), 5)
## [,1] [,2]
## [1,] 0.65050729 0.1725221
## [2,] 0.05174598 0.3434398
## [3,] -0.91056310 0.1138733
## [4,] 0.18131010 -0.7286614
## [5,] 0.40811952 1.8288346
这样直接在当前的运行环境中,就输出了代码和运行结果。
5. 格式化函数定义
通过usage函数可以只打印出函数定义,跳过函数细节。以var函数为例,输入var,默认会打印出一个函数细节。
> var
function (x, y = NULL, na.rm = FALSE, use)
{
if (missing(use))
use <- if (na.rm)
"na.or.complete"
else "everything"
na.method <- pmatch(use, c("all.obs", "complete.obs", "pairwise.complete.obs",
"everything", "na.or.complete"))
if (is.na(na.method))
stop("invalid 'use' argument")
if (is.data.frame(x))
x <- as.matrix(x)
else stopifnot(is.atomic(x))
if (is.data.frame(y))
y <- as.matrix(y)
else stopifnot(is.atomic(y))
.Call(C_cov, x, y, na.method, FALSE)
}
<bytecode: 0x0000000008fad030>
<environment: namespace:stats>
> usage(var) # 通过usage,只打印函数定义
var(x, y = NULL, na.rm = FALSE, use)
有时候函数定义也很长,比如lm函数,通过usage的width参数可以控制函数的显示宽度。
> usage(lm)
lm(formula, data, subset, weights, na.action, method = "qr", model = TRUE, x = FALSE, y = FALSE, qr = TRUE, singular.ok = TRUE, contrasts = NULL, offset, ...)
> usage(lm,width=30) # usage的width参数,控制函数的显示宽度
lm(formula, data, subset, weights,
na.action, method = "qr", model = TRUE,
x = FALSE, y = FALSE, qr = TRUE,
singular.ok = TRUE, contrasts = NULL,
offset, ...)
6. GUI工具
tidy.gui函数是一个GUI的工具,可以在界面上编辑并格式化R代码。首先安装gWidgetsRGtk2库:
> install.packages("gWidgetsRGtk2")
also installing the dependencies ‘RGtk2’, ‘gWidgets’
打开GUI控制台:
> library("gWidgetsRGtk2")
> g = tidy.gui()
我们输入一段不太好看的代码,如图1-4所示。
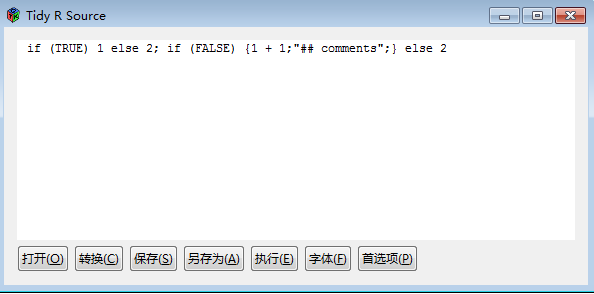
图1-4 tidy的GUI
点击“转换”,结果如图1-5所示,可以看到,在GUI的编辑器中,R语言的代码被格式化了!
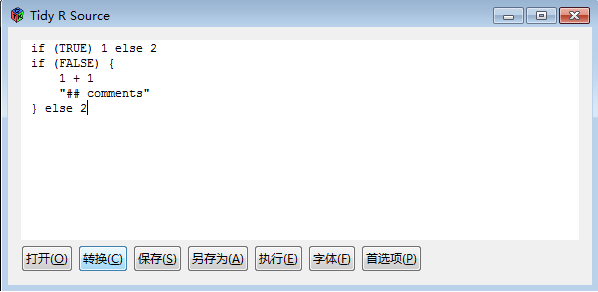
图1-5 格式化后的代码
7. 格式化目录中的文件
tidy.dir函数可以批量格式化文件,对目录中的所有文件进行格式化操作。
- 新建目录:dir
- 在目录dir中,新建两个R脚本文件:dir.r, dir2.r
~ mkdir dir # 新建目录 dir
~ cd dir
~ vi dir.r # 用vi新建文件dir.r
a<-1+1;a;matrix(rnorm(10),5);
~ vi dir2.r
if(a>2) { b=c('11',832);"#a>2";} else print('a is invalid!!')
执行tidy.dir:
> tidy.dir(path="dir")
tidying dir/dir.r
tidying dir/dir2.r
分别查看dir.r和dir2.r:
~ vi dir.r
a <- 1 + 1
a
matrix(rnorm(10), 5)
~ vi dir2.r
if (a > 2) {
b = c("11", 832)
"#a>2"
} else print("a is invalid!!")
我们发现不规则的代码,已经被格式化了!!
1.4.4 formatR的源代码解析
通过上面的使用,我们不难发现,formatR包的核心函数就是tidy.source函数,从github上面找到源代码:https://github.com/yihui/formatR/blob/master/R/tidy.R。我将在代码中增加注释:
tidy.source = function(
source = 'clipboard', keep.comment = getOption('keep.comment', TRUE),
keep.blank.line = getOption('keep.blank.line', TRUE),
replace.assign = getOption('replace.assign', FALSE),
left.brace.newline = getOption('left.brace.newline', FALSE),
reindent.spaces = getOption('reindent.spaces', 4),
output = TRUE, text = NULL,
width.cutoff = getOption('width'), ...
) {
if (is.null(text)) { # 判断输入来源为剪贴板
if (source == 'clipboard' && Sys.info()['sysname'] == 'Darwin') {
source = pipe('pbpaste')
}
} else { # 判断输入来源为字符串
source = textConnection(text); on.exit(close(source))
}
text = readLines(source, warn = FALSE) # 按行读取来源数据
if (length(text) == 0L || all(grepl('^\\s*$', text))) { # 大小处理
if (output) cat('\n', ...)
return(list(text.tidy = text, text.mask = text))
}
if (keep.blank.line && R3) { # 空行处理
one = paste(text, collapse = '\n') # record how many line breaks before/after
n1 = attr(regexpr('^\n*', one), 'match.length')
n2 = attr(regexpr('\n*$', one), 'match.length')
}
if (keep.comment) text = mask_comments(text, width.cutoff, keep.blank.line) # 注释处理
# 把输入的R代码,先转成表达式,再转回字符串。用来实现对每个语句的截取。
text.mask = tidy_block(text, width.cutoff, replace.assign && length(grep('=', text)))
text.tidy = if (keep.comment) unmask.source(text.mask) else text.mask # 对注释排版
text.tidy = reindent_lines(text.tidy, reindent.spaces) # 重新定位缩进
if (left.brace.newline) text.tidy = move_leftbrace(text.tidy) # 扩号换行
if (keep.blank.line && R3) text.tidy = c(rep('', n1), text.tidy, rep('', n2)) # 增加首尾空行
if (output) cat(paste(text.tidy, collapse = '\n'), '\n', ...) # 在console打印格式化后的结果
invisible(list(text.tidy = text.tidy, text.mask = text.mask)) # 返回,但不打印结果
}
1.4.5 源代码中的Bug
在读源代码的过程中,我发现有一个小问题,即在R 3.0.1版本,没有对向右赋值操作(->)进行处理。我已经就这个问题给作者提Bug了,参见https://github.com/yihui/formatR/issues/31。
Bug测试代码:
> c('11',832)->x2
> x2
[1] "11" "832"
> tidy.source(text="c('11',832)->x2")
c("11", 832) <- x2
> tidy.eval(text="c('11',832)->x2")
c("11", 832) <- x2
Error in eval(expr, envir, enclos) : object 'x2' not found
Bug已修复
作者回复:这个问题已经在R 3.0.2中修正了。
> formatR::tidy.source(text="c('11',832)->x2")
x2 <- c("11", 832)
> sessionInfo()
R version 3.0.2 (2013-09-25)
Platform: x86_64-pc-linux-gnu (64-bit)
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] formatR_0.10.3
formatR包提供的功能非常实用,特别是读别人写的不规范的代码的时候。建议各IDE厂商能把formatR作为标准的格式化工具直接嵌入编辑器的工具里面。让我们把读别人的代码,也变成一件快乐的事情吧。